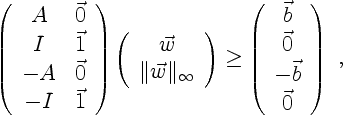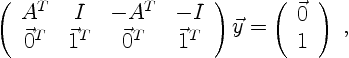|
|
|
To: 6.2.3 Adding vortices |
The strategy for finding a redistribution solution was formulated in the previous subsection 6.2.1; it reduces to the standard mathematical problem of finding the least maximum norm solution to a linear system of equations. Van Dommelen [235] used an ad hoc procedure to solve this problem [236]. However, in this thesis we have adopted a scheme developed by Abdelmalek [1]. This choice was based on some numerical experiments that showed that the method below usually takes less computational time. The procedure of Van Dommelen tends to be somewhat more robust on poorly conditioned systems, but we have adopted a Gram-Schmidt orthogonalization of the rows of the matrix as a standard preconditioning.
We do point out that the procedure of Van Dommelen has the following advantages: (a) it allows the iterations to be terminated early: even without convergence, the solution might satisfy the positivity condition; (b) the method provides a lower bound on the least maximum that might be used to predict early that a system does not have an acceptable solution; and (c) it might be extended to allow the solution at the previous time-step to be used as a starting point of the iterations. More research is needed, but the procedure below was found to be reliable and converged well.
Our starting point is the linear system of equations
The problem of finding a least maximum solution to a general linear
system may be formulated as a linear programming problem.
This is achieved by considering the maximum norm
![]() as another unknown. Casting equalities as the two inequalities
as another unknown. Casting equalities as the two inequalities ![]() and
and
![]() , this yields:
, this yields:
Abdelmalek [1]
points out that there are advantages to solving the dual problem.
The dual maximizes
| (6.9) |
The advantage is that an initial feasible solution is easy to find, so that no slack variables are needed. Further, due to the special structure of the matrix, the only storage needed is for the original matrix and a few vectors. This also reduces the work required to find the optimal solution.
The simplex method [82] requires a number of different tolerances to be specified a priori. We followed the recommendations of Clasen [62]. Convergence occurred typically within about 12 vertex interchanges in the simplex method.